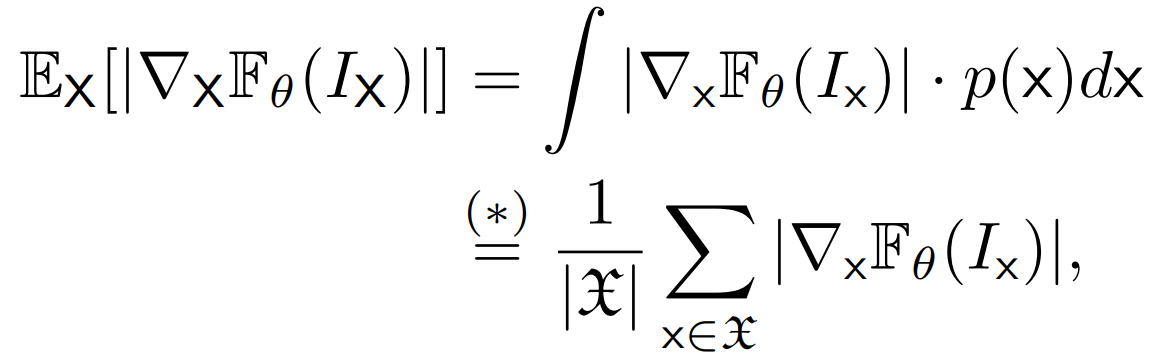Abstract
Deep learning models achieve high predictive performance but lack intrinsic interpretability, hindering our understanding of the learned prediction behavior.
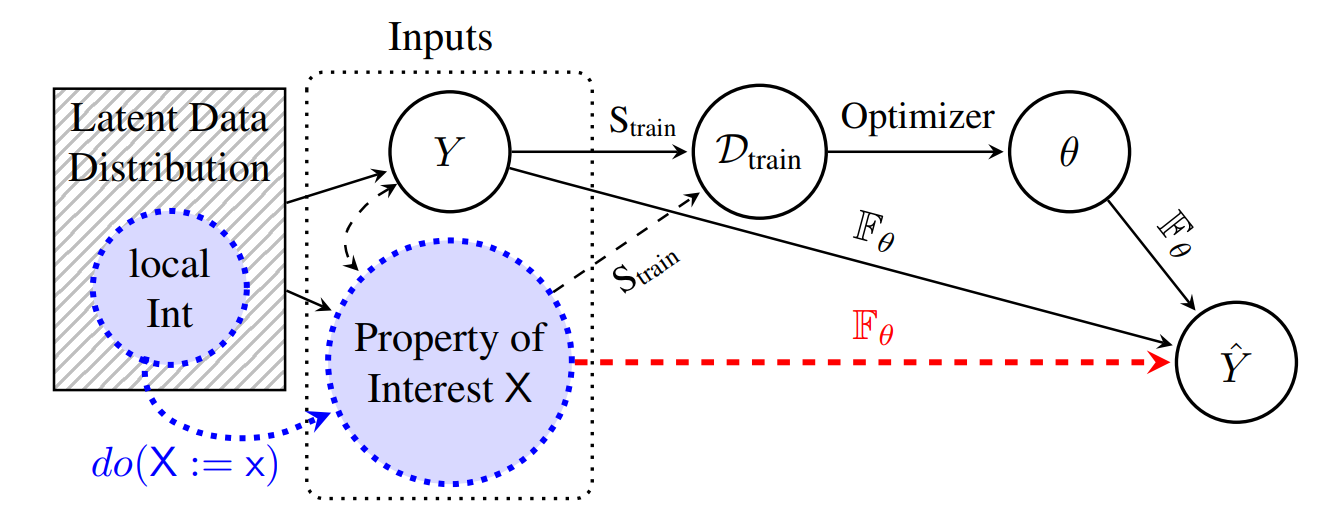
Existing local explainability methods focus on associations, neglecting the causal drivers of model predictions.
Other approaches adopt a causal perspective but primarily provide global, model-level explanations.
However, for specific inputs, it's unclear whether globally identified factors apply locally.
To address this limitation, we introduce a novel framework for local interventional explanations by leveraging recent advances in image-to-image editing models.
Our approach performs gradual interventions on semantic properties to quantify the corresponding impact on a model's predictions using a novel score, the expected property gradient magnitude.
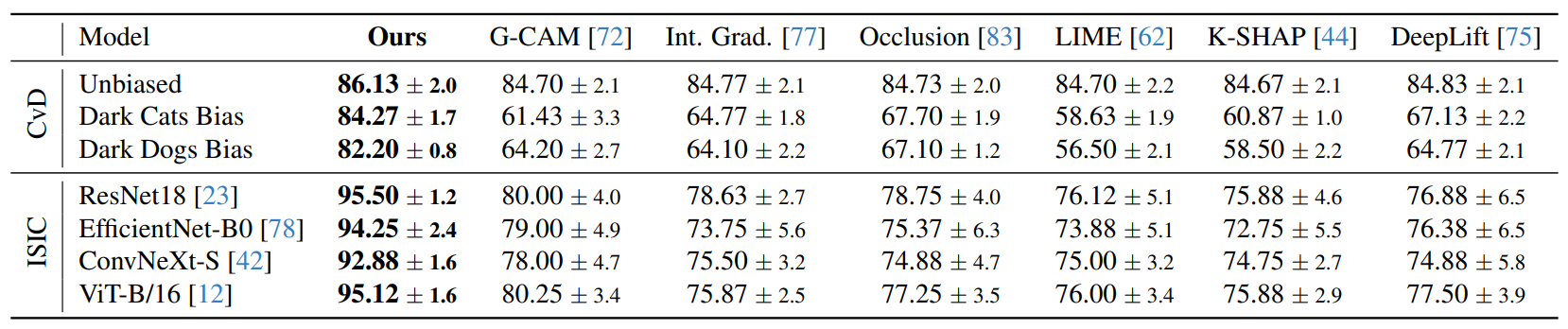
We demonstrate the effectiveness of our approach through an extensive empirical evaluation on a wide range of architectures and tasks.
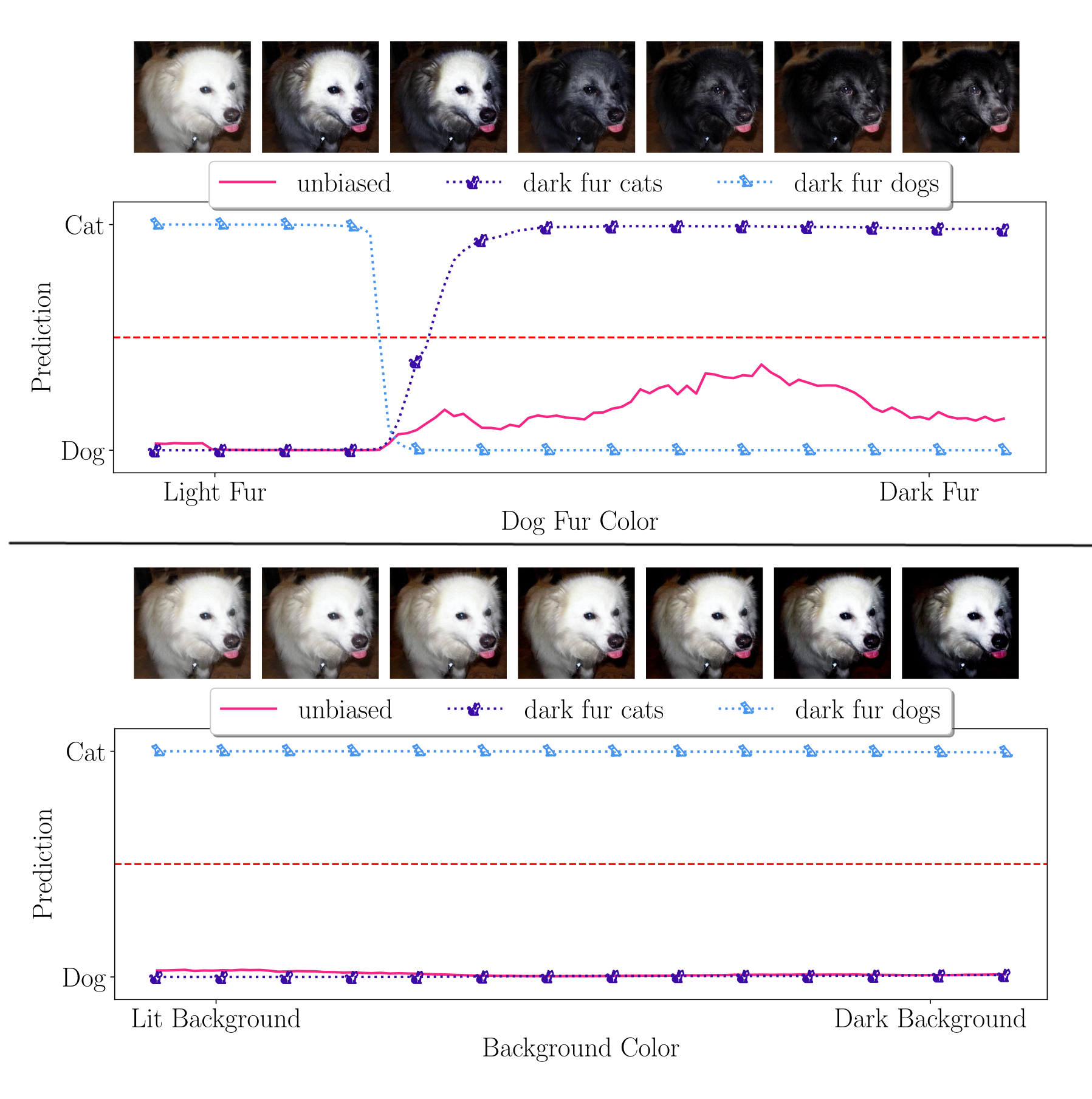
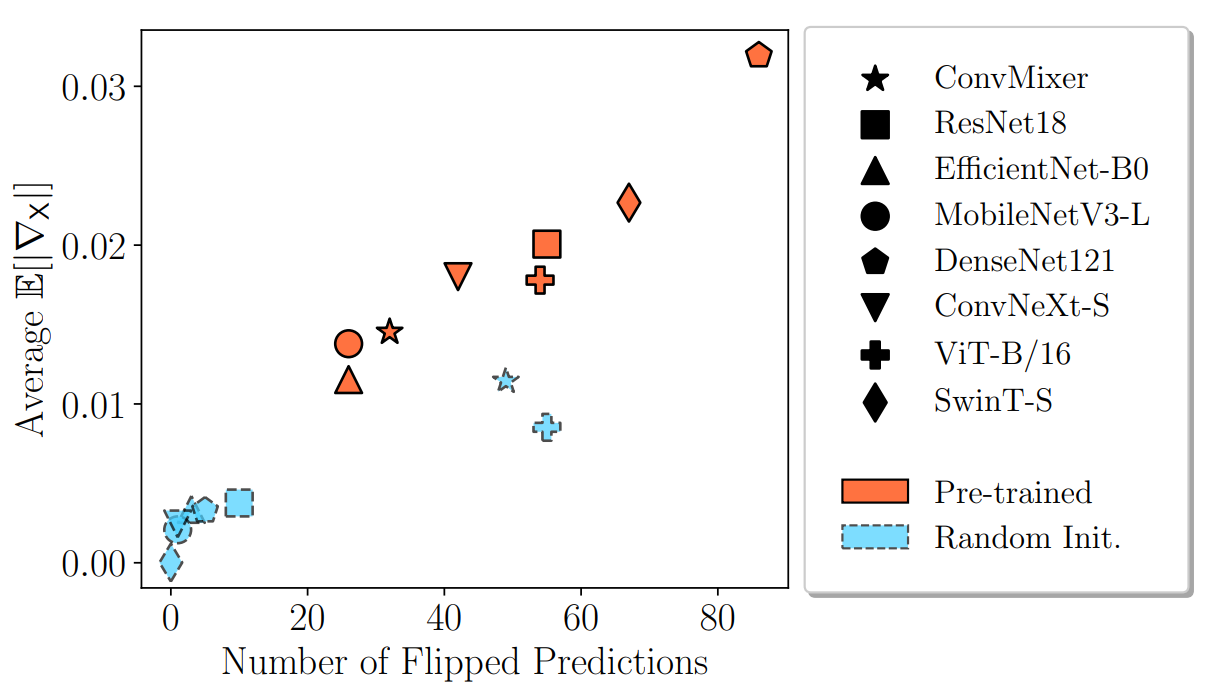
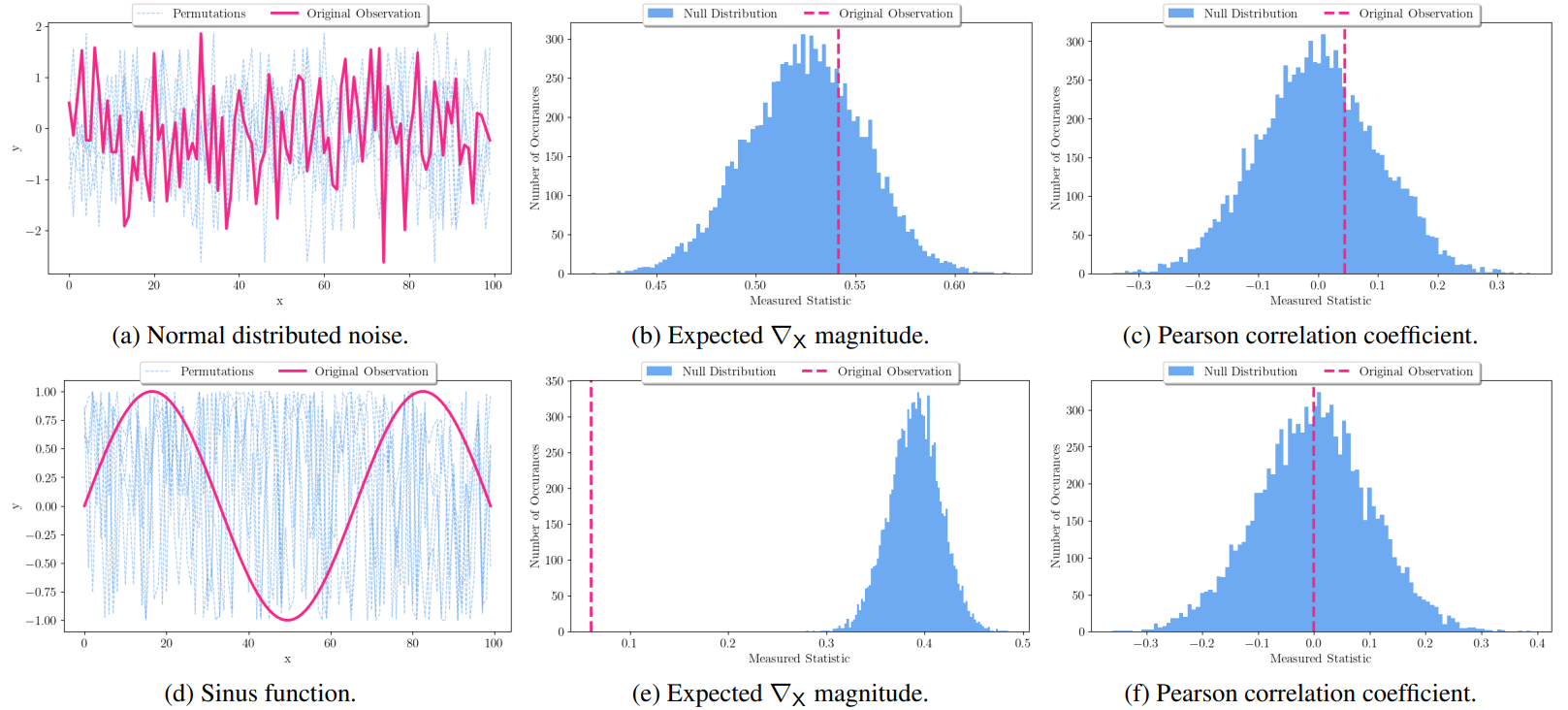
First, we validate it in a synthetic scenario and demonstrate its ability to locally identify biases.
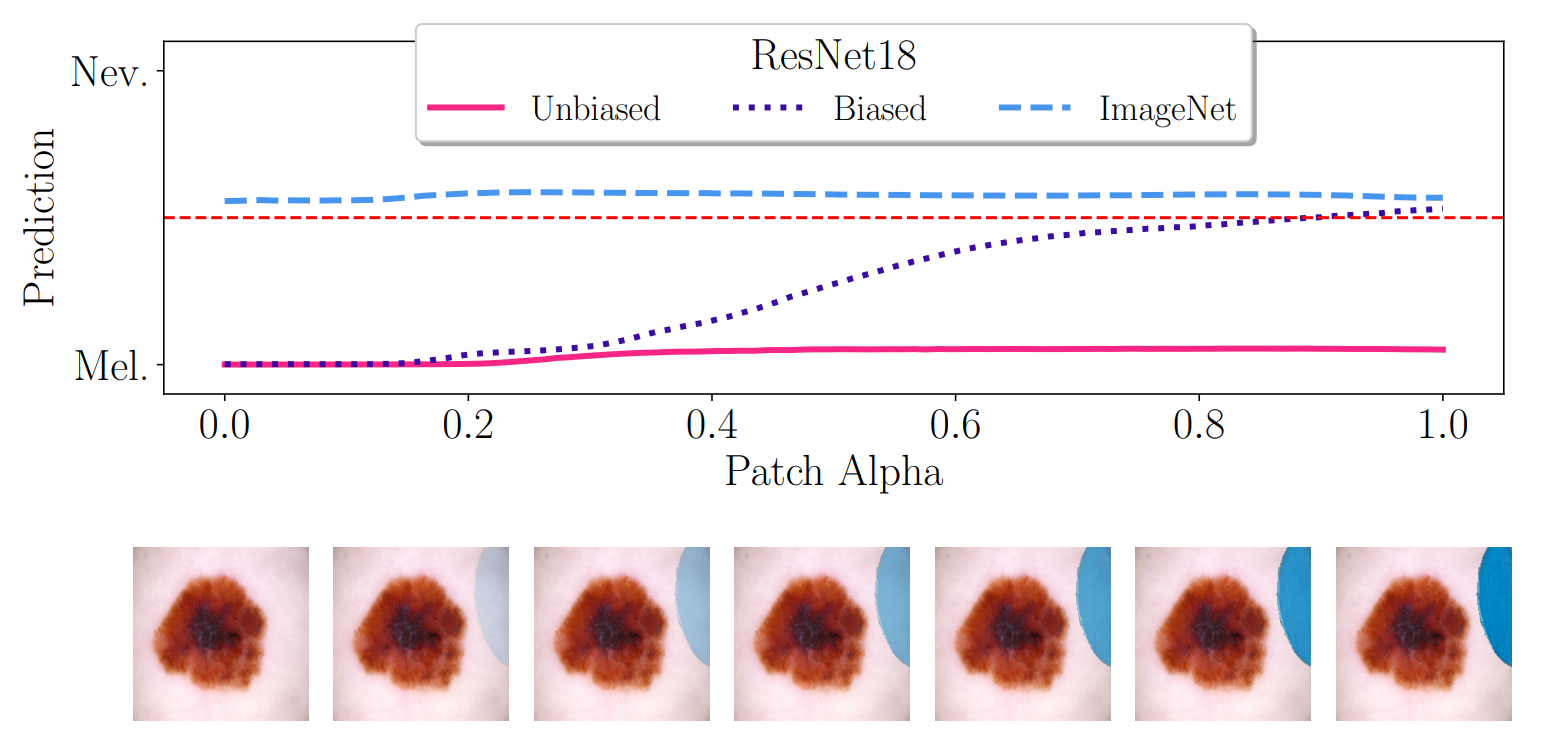
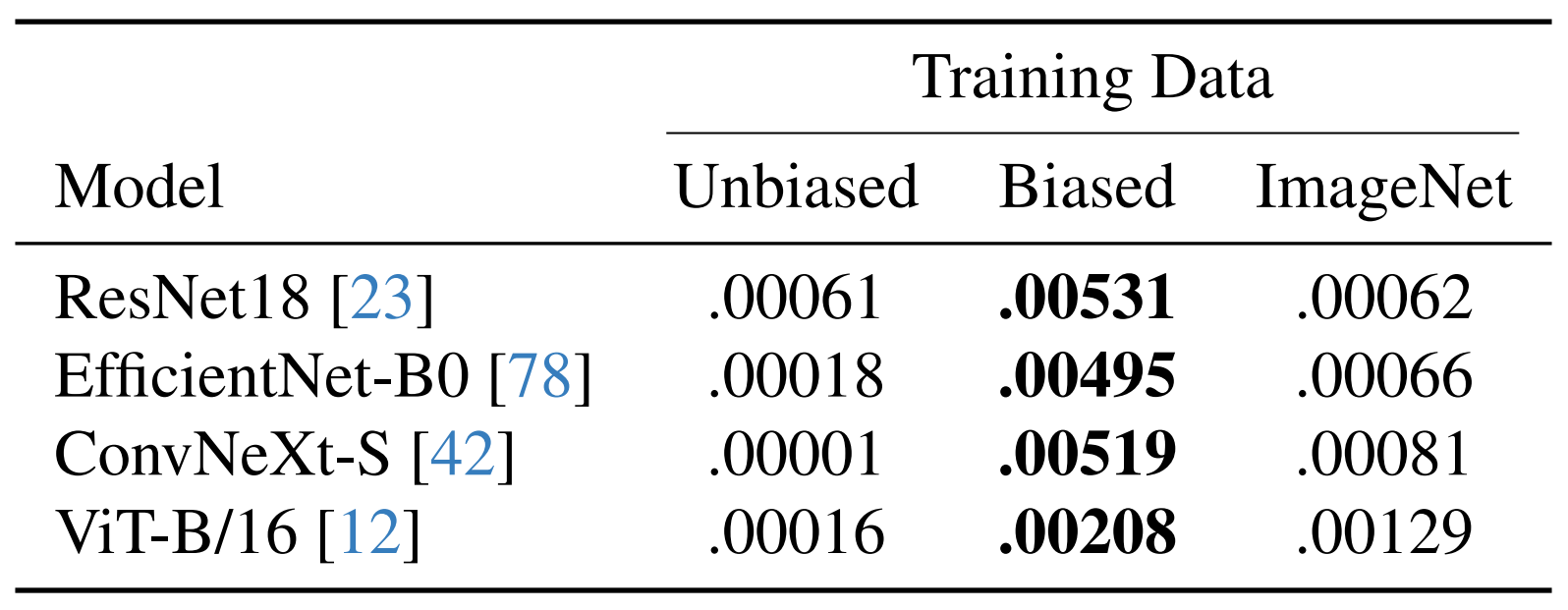
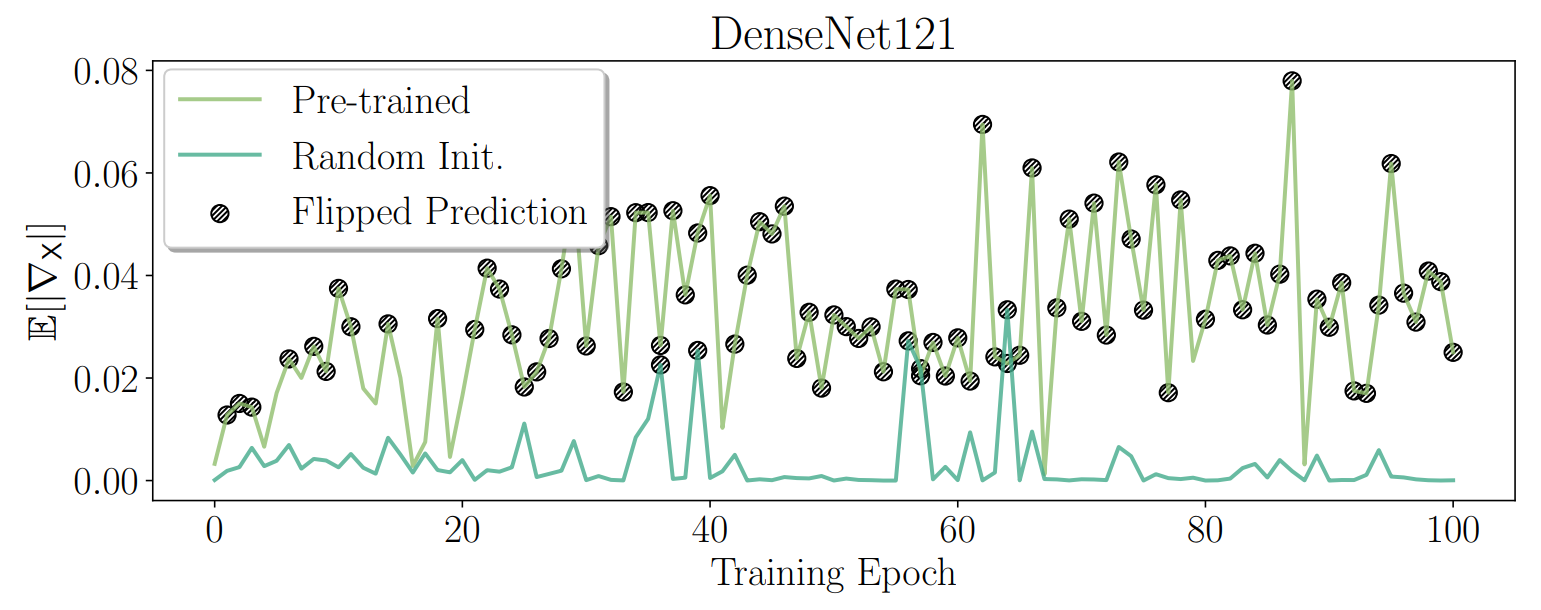
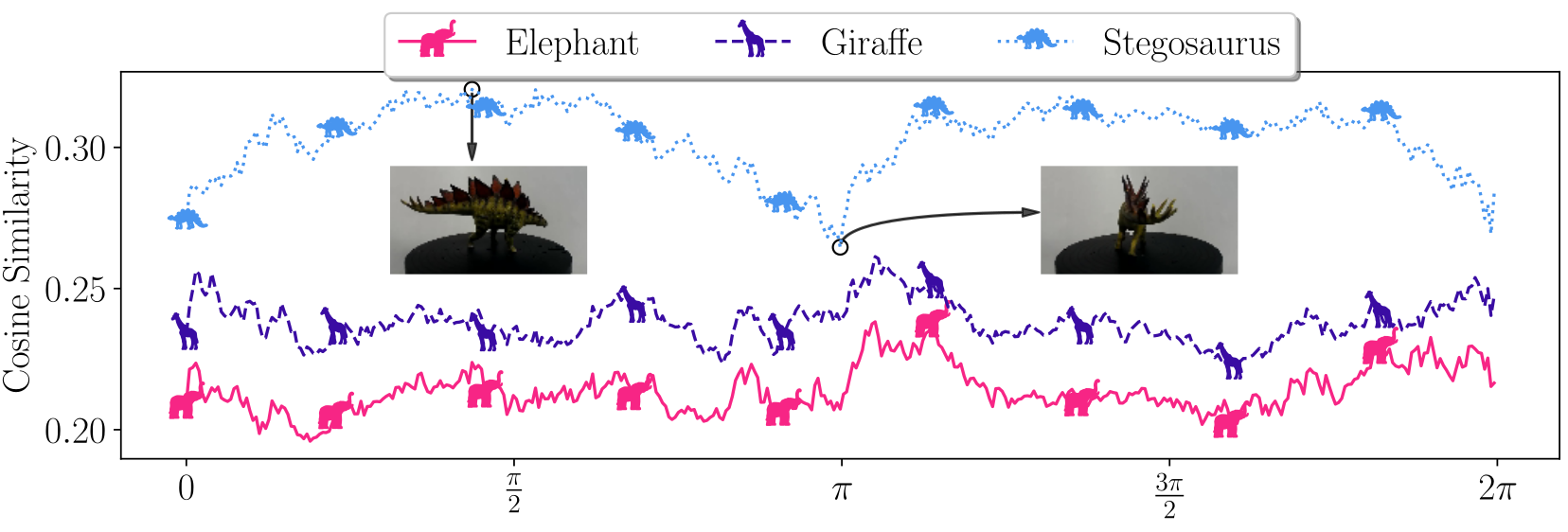
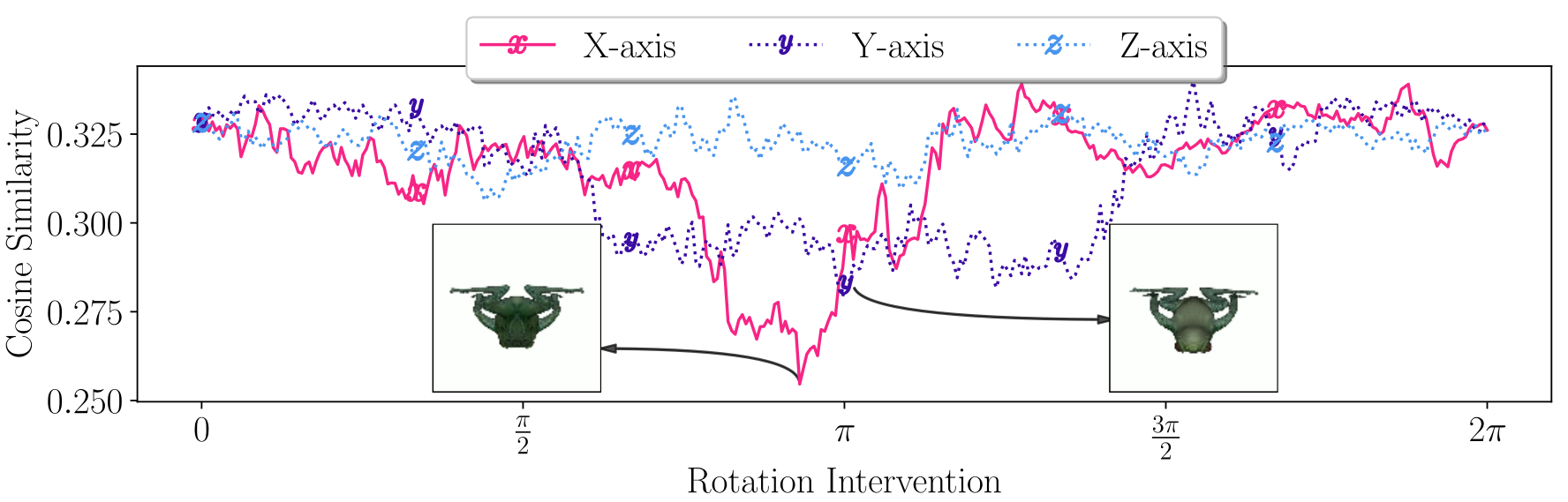
Afterward, we apply our approach to investigate medical skin lesion classifiers, analyze network training dynamics, and study a pre-trained CLIP model with real-life interventional data.
Our results highlight the potential of interventional explanations on the property level to reveal new insights into the behavior of deep models.